Frédéric
Castonguay
CASF09028208
Rapport de conférence
Présenté à
Monsieur Vladimir Makarenkov
Dans le cadre du cours
Bif7002 : Séminaire de bioinformatique
26 mars 2008
Université
du Québec à Montréal
Sommaire
Architectures
de parallélisation
MPI – Message Passing Interface
CUDA –
Compute Unified Device Architecture
Introduction
La parallélisation d’algorithme se base sur le principe que la plupart des problèmes peuvent être divisés en sous-problèmes de plus petites tailles pouvant être résolus simultanément. Puisque la vitesse des processeurs modernes est maintenant relativement limitée, cette faculté s’avère plus que nécessaire lorsque l’on doit traiter un nombre imposant de données. De plus, La communication et la synchronisation des différents sous-problèmes s’avèrent souvent très complexe, ce qui limite parfois les gains en performance.
Bien évidemment, il existe diverses formes de parallélisation d’algorithmes tel que le parallélisme par flux, de contrôle, et de données. Par contre, toutes ces méthodes ont un objectif commun, soit d’obtenir une certaine forme d’accélération comparativement à un algorithme non-parallèle traditionnel. Le traitement parallèle de données implique également un besoin matériel supplémentaire, tel qu’un processeur additionnel, un processeur à noyau multiple, ou même des ordinateurs supplémentaires communiquant par l’entremise d’un réseau.
Ce papier présentera donc en détail diverses stratégies et architectures de parallélisation. Deux environnements récents seront également explorés. CUDA qui permet d’affecter des tâches au processeur graphique (GPU) et MPI une librairie standard de passage de messages.
Architectures de
parallélisation
Les quatre
architectures présentées font partie de la classification de Flynn, proposé la
première fois en 1966 par Michael J.Flynn. Cette taxonomie est basée sur le
nombre de flots d’instructions et de données disponible sur l’architecture.
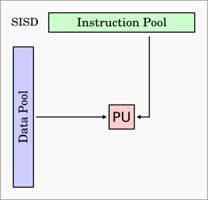 SISD – Single Instruction Single Data
SISD – Single Instruction Single Data
Cette
architecture n’offre aucun parallélisme autant au niveau des instructions que
des données. Elle exécute une suite d’instructions agissant sur un seul flot de
données.
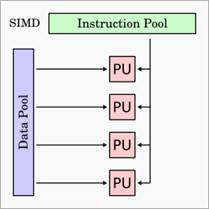
SIMD – Single Instruction Multiple Data
Cette
architecture offre un type de parallélisme au niveau des données. En effet, une
même suite d’instructions est exécutée simultanément sur plusieurs flots de
données. Donc, à un certain instant, chacun des processeurs exécute la même
instruction sur des données différentes.
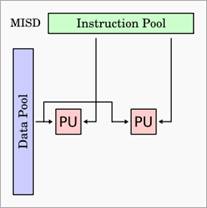 MISD – Multiple Instruction Single Data
MISD – Multiple Instruction Single Data
Sous cette
architecture, plusieurs instructions sont exécutées sur le même flot de
données. Peu de problèmes nécessite une telle architecture, on retrouve donc
peu ou pas d’ordinateurs MISD commercialisés.
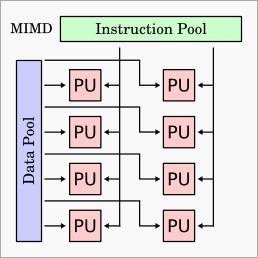 MIMD – Multiple Instruction Multiple Data
MIMD – Multiple Instruction Multiple Data
Comme son nom
l’indique, cette architecture permet d’exécuter plusieurs flots d’instructions
sur différents flots de données qui sont tous indépendants. Cette architecture
est actuellement la plus utilisé dans le développement des superordinateurs
puisque elle est facilement extensible et peu couteuse.
La mémoire du modèle MIMD peut soit être partagé ou distribuée. Si elle est
partagée, tous les unités de traitement ont accès à la même mémoire et tout
changement se produisant sur celle-ci est donc immédiatement perçu par les
autres unités. Par contre, si la mémoire est distribuée, chaque unité de
traitement possède sa propre mémoire et l’utilisation d’un inter-logiciel est
donc requise pour effectuer la synchronisation entre celles-ci. Il existe
également plusieurs sous divisions du MIMD, ce qui spécifie davantage le modèle
architectural.
SPMD – Single Program Multiple Data
Les processeurs
autonomes du modèle MIMD exécutent simultanément mais indépendamment le même
programme sur différentes données.
MPMD – Multiple Program Multiple Data
Les processeurs
autonomes du modèle MIMD exécutent simultanément plusieurs programmes
indépendants sur différentes données.
MPI – Message Passing Interface
MPI est un protocole de communication standardisé pour la conception de
programmes nécessitant le transfert de messages. L’interface tente donc de
fournir diverses méthodes afin de fournir un environnement pratique, efficace,
flexible et le plus portable possible. Dans les environnements distribués ou
les communications entre les diverses entités sont parfois conçus
indépendamment, l’adoption de standards est plus que bénéfique. Il existe
plusieurs implémentations de MPI, notamment en Fortran, C et C++.
MPI permet la topologie virtuelle, la
synchronisation et la communication entre les diverses entités formant les
unités de traitement.
Communications
point à point
Le type de communication le plus simpliste offert par MPI est par point à
point. Une communication point à point s’effectue d’une seule unité de
traitement vers une seule autre unité de traitement. Les routines qui
permettent d’effectuer les communications points à point sont très nombreuses
et variés. En bref, les routines d’envoi, de réception, de vérification et de
complétion sont disponibles selon les modes suivants.
|
Envoi |
Réception |
Vérification |
Complétion |
|
Bloquant Non-Bloquant Persistant |
Bloquant Non-Bloquant Persistant |
Bloquant Non-Bloquant |
Bloquant Non-Bloquant |
Table 1 : Modes
de communications point à point selon type de routine
Les communications bloquantes attendront
que les données soient transmissent ou reçues avec succès avant de continuer
l’exécution du programme. Par contre, les communications non-bloquantes
n’attendent pas que la communication soit complétée avant de poursuivre
l’exécution. Ceci permet donc d’utiliser le temps dédié aux communications pour
effectuer d’autres calculs et ainsi obtenir des gains en performance.
Les communications persistantes
permettent tant qu’a-elle de réduire le traitement des messages qui doivent
constamment être envoyés entre deux unités de traitement. Les communications
persistantes communiqueront donc continuellement le même message sans avoir à
initialiser l’envoi et la réception à chaque fois. Ces communications persistantes
sont de type non-bloquant.
Communications
collectives
MPI permet également la communication collective. Pour ce faire, on doit
d’abord définir différents groupes parmi les unités de traitement disponible.
Ensuite, il faut affecter à chacun des groupes un communicateur qui permettra
de diffuser un message parmi toutes les unités du groupe. Par exemple, dans le
diagramme ci-dessous il serait possible de transmettre un message uniquement aux
entités du groupe 2 par l’entremise du communicateur MPI_COMM_GROUP_2.
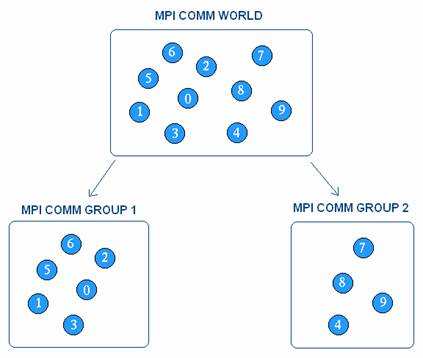
Figure 1 : Exemple de groupes et communicateurs
Topologies
virtuelles
Les unités d’un groupe peuvent également être ordonnées sous une topologie
virtuelle afin de faciliter les communications entre ceux-ci, selon le problème
à résoudre. Cette topologie peut également aider le moteur d’exécution à
allouer les différentes tâches aux composants matériels disponibles. Il est
important de prendre note qu’il s’agit de topologies virtuelles, ce qui n’a
aucun lien avec l’organisation physique de la machine parallèle.
Performance
Plusieurs facteurs peuvent affecter la
performance de MPI. L’exemple le plus
probant est la taille des messages. Habituellement, la performance de MPI
augmente avec la taille des messages. Les deux graphes[1] ci-dessous démontrent que l’augmentation de la
taille des messages améliore la vitesse de transmission des messages :
|
|
|
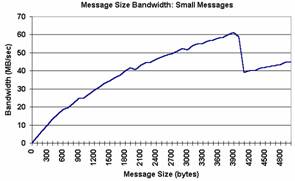
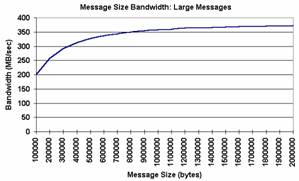
Figure 2 :
Comparaison des performances de MPI selon la taille des messages
CUDA –
Compute Unified Device Architecture
Depuis quelques années, l’utilisation
des GPU ne se restreint plus aux calculs des pixels de notre écran. En effet,
NVidia propose une technologie qui permet d’utiliser la puissance de calcul de
nos cartes graphiques à d’autres fins. Bien évidemment, les cartes graphiques
disposent d’un processeur (GPU) différent des processeurs centraux (CPU), ce
qui implique qu’ils sont destinés à résoudre un type différent de problèmes.
GPU et
CPU
Due à son architecture interne, le GPU ne permet pas de calculer des
opérations complexes telles que le CPU le permet. En effet, on attend plutôt du
GPU qu’il puisse traiter extrêmement rapidement un nombre élevé de tâches
simples et indépendantes. Le nombre largement supérieur d’« Arithmetic
logic unit » (ALU) du GPU explique cette spécificité. Une énorme
proportion du GPU est donc dédiée à l'exécution, contrairement au CPU qui consacre
une portion importante à l’unité de contrôle et à la mémoire cache.
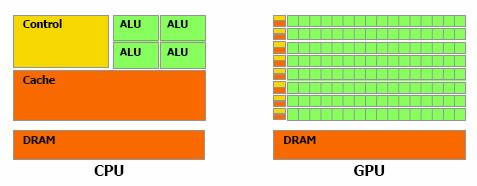
Figure 3 :
Architecture GPU vs CPU
Évolution
des GPU
Puisque les GPU et les CPU sont
conçues pour résoudre des problèmes différents, l’évolution de ceux-ci diffère
également. En effet, depuis quelques années la puissance de calcul des GPU à
évolué exponentiellement contrairement au CPU qui semble déjà avoir plafonné. Voici
un diagramme qui présente l’évolution de la carte graphique GeForce
comparativement au processeur central d’Intel.
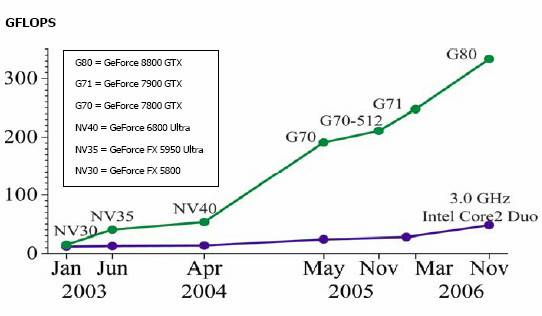
Figure 4 : Évolution
des GPU et CPU
Architecture
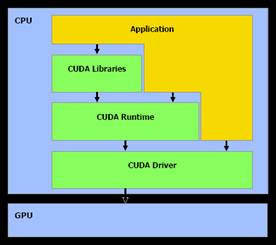
L’architecture de CUDA est composée
d’un pilote, d’un moteur d’exécution, et de diverses librairies. CUDA possède
son compilateur spécialement conçu pour
rediriger les tâches non exécuté sur le GPU vers le compilateur classique du
système. L’API de CUDA fait abstraction du matériel, il est donc beaucoup plus
facile et rapide de développer en CUDA qu’en « Close to Metal » (CMT),
technologie semblable mais qui ne permet pas de faire cette abstraction.
|
Le pilote CUDA est l’intermédiaire entre
le code compilé et le GPU. Le moteur d’exécution, est une interface qui
permet de faire abstraction des diverses implémentation logicielles effectués
au niveau du pilote. Quoi que cette interface permette de développer du code
exécutable plus rapidement, celle-ci peut être rapidement contournée par les
développeurs afin d’utiliser directement le pilote CUDA si nécessaire. |
Figure 5 : Architecture de CUDA |
CUDA permet l’adressage classique DRAM
pour plus de flexibilité. C'est-à-dire qu’il est possible d’écrire et de lire à
n’importe quelle position dans la DRAM, tel un CPU. Afin d’accélérer ces
opérations de lectures et d’écritures, CUDA dispose d’une mémoire cache partagé
ayant une rapidité d’accès plus élevé que la DRAM. Cette mémoire cache permet
donc de rapprocher les données de la DRAM des ALU, ce qui rendra l’exécution
moins dépendante de la borne passante dédié à la DRAM.
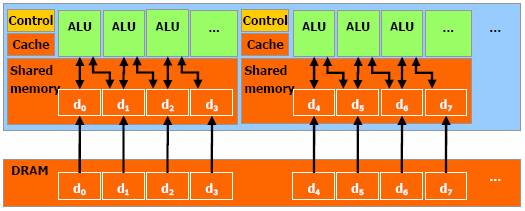
Figure 6 : Mémoire
partagée et accès à la DRAM
Modèle
de programmation
Lorsque l’on programme en CUDA, il
faut considérer le GPU comme une unité de traitement capable d’exécuter un
nombre important de « thread » en parallèle. On peut également le
visualiser comme un coprocesseur du CPU responsable de résoudre un type
spécifique de problème. Par exemple, un calcul (fonction) qui doit être exécuté
plusieurs fois sur un nombre indépendant de données est un candidat parfait
pour être affecté au GPU sous forme de plusieurs threads.
Les threads sont premièrement divisés
en blocs qui peuvent interagir entre eux et partager des données rapidement. Les
blocs possèdent un nombre limité de thread. Cependant, les blocs qui exécutent
la même fonction peuvent être regroupés en grilles de blocs. Ce mécanisme
implique cependant un temps de traitement supplémentaire puisqu’il est
impossible de synchroniser les différents blocs entre eux. Ce modèle permet
d’exécuter une fonction sur différentes machines ayant des capacités de
parallélisation différentes sans avoir à recompiler le code. La machine
répartira donc ces blocs selon ces ressources de calcul parallèle disponible.
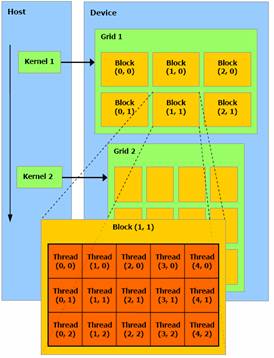
Figure 7 : Organisation
des blocs et threads
Performance
Divers facteurs peuvent affecter les
performances de CUDA. Voici deux graphiques qui permettent de comparer les
gains de performance lorsque l’on fait varier le nombre et la complexité des
différents blocs. Il ne s’agit pas de comparer le CPU et le GPU, mais plutôt de
visualiser le gain en performance de chacun de ceux-ci.
Le diagramme suivant présente le temps de calcul pour un nombre de blocs
variant entre 1 et 64. Chacune des exécutions possède donc le même nombre
d’instructions, mais celles-ci sont réparties dans un nombre variable de blocs.
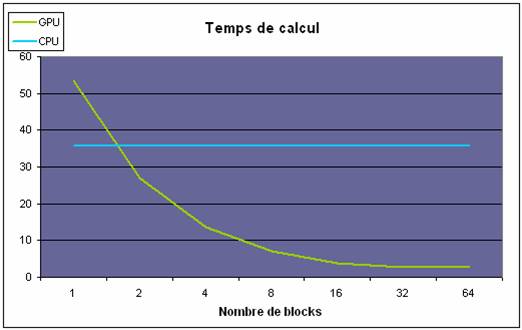
Figure 8 : Temps
de calcul vs nombre de blocs[2]
Pour le CPU le temps de traitement reste constant. Par contre, le GPU
démontre une accélération considérable à mesure que le nombre de blocs
augmente. Un temps de traitement initial est supplémentaire pour le GPU, mais
l’accélération est colossal lorsque l’on utilise 16 blocs ou plus.
Le diagramme suivant démontre le temps de calcul par rapport à la taille
des blocs à exécuter, soit leur nombre d’instructions respectives. Pour ce
test, le nombre de blocs à été fixé à 32.
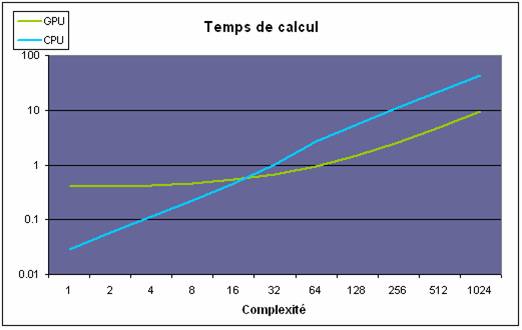
Figure 8 : Temps
de calcul vs complexité des blocs[3]
Encore
une fois, le temps initial requis par le GPU est plus élevé que celui
nécessaire pour le traitement sur CPU. Par contre, le temps de calcul du CPU augmente
linéairement et est rapidement surpassé par le GPU qui augmente beaucoup plus
lentement avant d’atteindre une accélération linéaire après une certaine
taille. Cette indication peut supposer qu’il est préférable de concevoir des
blocs de tailles de plus grandes tailles.
Conclusion
Il existe un nombre considérable de stratégies possibles afin d’effectuer
de la parallélisation d’algorithmes et ainsi obtenir des gains de performance
considérable. Cependant, la synchronisation et l’organisation des différentes
tâches afin de résoudre un problème s’avère un des plus grands défis des
algorithmes parallèles.
MPI est déjà un standard en ce qui concerne les communications par passage
de message. Standard principalement utilisé dans le développement de machines
parallèles distribuées sur diverses machines (Clusters).
CUDA est une nouvelle technologie qui permet l’allocation de tâches au
processeur graphique sous formes de blocs de thread. Si jamais sont succès se
fait ressentir, il ne faudrait pas s’étonner de voir une puce combinant CPU et
GPU.
Références
Parallel Computer
Taxonomy
http://www.gigaflop.demon.co.uk/comp/chapt7.htm
SP Parallel
Programming Workshop
http://www.mhpcc.edu/training/workshop/mpi/MAIN.html
MPI: A
Message-Passing Interface Standard
http://www.mpi-forum.org/docs/mpi1-report.pdf
MPI The
Complete Reference
http://www.netlib.org/utk/papers/mpi-book/mpi-book.html
CUDA
Programming Guide
http://developer.download.nvidia.com/compute/cuda/1_1/NVIDIA_CUDA_Programming_Guide_1.1.pdf
Nvidia CUDA : aperçu
http://www.hardware.fr/articles/659-1/nvidia-cuda-apercu.html