Date: Mercredi, 26 avril 1995.
Durée: 1 1/2 heures (9:00 à 10:30).
#1) Soit t, un tableau, et a, un arbre binaire, deux structures de données définies respectivement par les types suivants:
Soit deux procédures -- sommeTableau et sommeArbre -- servant à calculer, respectivement, la somme des éléments ( Real) d'une structure de données du type indiqué (Tableau vs. Arbre).
Quel principe permet de justifier/expliquer l'affirmation suivante? Expliquez brièvement votre réponse.
L'utilisation d'un cache de données aurait très certainement un effet positif sur la performance de la procédure sommeTableau. Par contre, l'effet ne serait probablement pas aussi intéressant dans le cas de la procédure sommeArbre.
#2) Une usine de lampes possède deux chaînes de montage et assemblage.
La 1ère chaîne, ![]() , comporte 3 étapes ayant les temps
d'exécution suivants (en minutes):
, comporte 3 étapes ayant les temps
d'exécution suivants (en minutes):
![]()
La 2ième chaîne, ![]() , comporte 5 étapes ayant les temps
suivants (minutes):
, comporte 5 étapes ayant les temps
suivants (minutes):
![]()
Dans les deux cas, une étape ne peut amorcer l'assemblage d'une nouvelle partie que si les étapes précédentes et suivantes sont complétées.
a) Déterminez le nombre maximum de lampes M pour lequel le temps
total d'assemblage des M lampes, sur la chaîne ![]() , sera
inférieur ou égal au temps sur
, sera
inférieur ou égal au temps sur ![]() . (En d'autres mots, si le
nombre de lampes à assembler est
. (En d'autres mots, si le
nombre de lampes à assembler est ![]() M, alors
M, alors ![]() sera plus
rapide (ou identique); sinon, si > M, alors
sera plus
rapide (ou identique); sinon, si > M, alors ![]() sera plus
rapide.)
sera plus
rapide.)
b) Pour un très grand nombre de lampes (i.e., asymptotiquement), de
combien la chaîne de montage ![]() sera-t-elle plus rapide que la
chaîne
sera-t-elle plus rapide que la
chaîne ![]() ?
?
#3) Dans le chapitre 6, la mise en oeuvre du processeur avec
un pipeline était basée sur la décomposition en 5 étapes de
l'exécution d'une instruction. Soit ![]() la machine avec le pipeline
à 5 étages du Chap. 6.
la machine avec le pipeline
à 5 étages du Chap. 6.
Soit alors ![]() la machine pour laquelle on utilise un pipeline à 4
étages plutôt que 5, pipeline dans lequel les étapes de
décodage (DI) et exécution (EX) sont regroupées en un (1) seul
étage. Une représentation schématisée du pipeline de la
machine
la machine pour laquelle on utilise un pipeline à 4
étages plutôt que 5, pipeline dans lequel les étapes de
décodage (DI) et exécution (EX) sont regroupées en un (1) seul
étage. Une représentation schématisée du pipeline de la
machine ![]() serait donc comme suit:
serait donc comme suit:
![]()
a) Quel serait le CPI moyen de la machine ![]() (pipeline à 4 étages)
en ignorant les aléas (données et branchement) et les défauts de
cache, pour un nombre suffisamment grand d'instructions exécutées?
(pipeline à 4 étages)
en ignorant les aléas (données et branchement) et les défauts de
cache, pour un nombre suffisamment grand d'instructions exécutées?
b) Un avantage d'un tel regroupement est que cela pourrait avoir un
impact positif sur les aléas de branchement. Supposons que la
condition associée à un branchement soit déterminée, pour
![]() et
et ![]() , au début de l'étape MEM, i.e., c'est seulement à
l'étape MEM que l'on sait si le branchement s'effectue ou non. Les
sous-questions suivantes (i et ii) examinent l'effet du pipeline à 4
étages sur différentes façons de traiter les branchements. On
suppose que les statistiques suivantes s'appliquent:
, au début de l'étape MEM, i.e., c'est seulement à
l'étape MEM que l'on sait si le branchement s'effectue ou non. Les
sous-questions suivantes (i et ii) examinent l'effet du pipeline à 4
étages sur différentes façons de traiter les branchements. On
suppose que les statistiques suivantes s'appliquent:
- Les instructions de branchement représentent 15% de toutes les instruction exécutées.
- Les branchement sont effectivement effectués (i.e., la condition est vraie) dans 40% des cas.
i) Supposons que la machine utilise la technique des branchements différés et que le compilateur, en moyenne, réussit à remplir efficacement une (1) seule case de délai de branchement. Quelle serait alors la pénalité moyenne de branchement?
ii) Supposons que la machine utilise une méthode dynamique de prédiction des branchements avec un taux de succès de 80%. Quelle serait alors la pénalité moyenne de branchement?
c) La décomposition en 4 étages pourrait avoir un effet positif sur certains aléas de données. Dans la suite d'instructions présentée plus bas, indiquez les aléas de données potentiels (i.e., en ignorant les envois possibles) qui existent dans le pipeline à 5 étages mais pas dans le pipeline à 4 étages. (Encerclez et reliez les registres appropriés.)
add $1, $2, $3 sub $6, $4, $5 or $4, $3, $6 and $9, $6, $1
#4) Soit un cache à correspondance directe contenant 4 blocs (4 lignes) de 4 mots et utilisant une stratégie d'écriture simultanée.
a) Pour chacun des accès mémoire suivants, indiquez s'il donnera lieu à un échec ou un succès de cache. Donnez aussi le contenu final du cache, en supposant que le mot à l' adresse k contienne la valeur 10*k et que le cache est initialement vide.
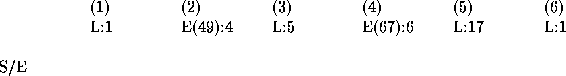
b) Pour les accès indiqués plus haut, le nombre d'échecs aurait-il été moins nombreux, identique ou plus nombreux pour les caches suivants:
i) Cache totalement associatif contenant 4 blocs de 4 mots et utilisant une stratégie d'écriture simultanée:
![]()
ii) Cache associatif par ensemble de 1 contenant 4 blocs de 4 mots et utilisant une stratégie de réécriture:
![]()
#5) Soit deux machines, ![]() et
et ![]() , ayant les
caractéristiques suivantes:
, ayant les
caractéristiques suivantes:
- La mise en oeuvre, dans les 2 cas, utilise un nombre variable de cycles résultant en un CPI moyen de 4 (lorsqu'on ignore les délais dûs aux fautes de cache).
- Une fois initié, le temps requis pour compléter un accès mémoire (instruction ou donnée) est, dans les deux cas, de 100 ns. (En d'autres mots, la pénalité pour un accès mémoire est de 100 ns.)
- Les deux machine possèdent un cache de 8 KB, commun aux instructions et données, ayant un taux de succès de 90%.
La différence essentielle entre ![]() et
et ![]() est la vitesse de
leur horloge:
est la vitesse de
leur horloge:
De plus, 30% des instructions exécutées sont des rangements/chargements.
Pour les questions a) et b) qui suivent, choisissez l'une des expressions suivantes pour indiquer la pénalité moyenne dûe aux fautes de cache:
a) Quelle est la pénalité moyenne dûe aux fautes de cache (en
nombre de cycles d'horloge) dans le cas de la machine ![]() ?
?
b) Quelle est la pénalité moyenne dûe aux fautes de cache (en
nombre de cycles d'horloge) dans le cas de la machine ![]() ?
?
c) En tenant compte des fautes de cache, quelle machine est la plus rapide et de combien?
#6) Parmi les énoncés suivants, encerclez ceux qui caractérisent uniquement les machines superscalaires, uniquement les machines à pipeline comme celles du chapitre 6, les deux types de machine ou aucun des deux types:
a) Le CPI moyen, dans le cas idéal, i.e., en ignorant les aléas, les défaut de cache et le remplissage du pipeline, est de 1.
![]()
b) Le temps total pour exécuter complètement une instruction donnée est de un (1) cycle.
![]()
c) Permet une forme de paralléllisme ``temporel'', i.e., permet qu'à un instant donné, plusieurs instructions soient en cours d'exécution, mais à des étapes de traitement différentes.
![]()
d) Le cache doit pouvoir fournir, à chaque cycle d'horloge, deux (2) ou plusieurs instructions.
![]()
#7) Certaines machines possédant un pipeline très profond -- i.e., avec un très grand nombre d'étages, par ex., 8, 10 ou même 14 étages -- sont dites `` superpipelinées''. Laquelle-lesquelles des affirmations suivantes permettent d'expliquer pourquoi de telles machines sont généralement plus performantes que des machines avec un pipeline moins profond (e.g., 3-5 étages). (Encerclez la-les réponse-s appropriée-s.)
a) Parce que l'augmentation du nombre d'étages permet de réduire la pénalité de branchement.
b) Parce que chaque étage étant plus court, la période d'horloge utilisée peut être plus courte, i.e., une fréquence d'horloge plus élevée peut être utilisée.
c) Parce que la présence d'unités fonctionnelles multiples, e.g., 2 ou plusieurs UAL entières, permet l'exécution de plusieurs instructions en parallèle (parallélisme spatial).