INF4110-10 Examen final (Automne 1998)
Examen final -- INF4110-10
Automne 1998
Examen final -- INF4110-10
Automne 1998
1. Table de hachage (10 pts)
On veut construire
un vérificateur d'orthographe intégré à un traitement de texte
(spelling checker). Pour ce faire, on a accès à un gros
fichier contenant l'ensemble des mots valides. Toutefois, comme
l'espace mémoire est limité, il n'est pas possible de charger tous
ces mots dans un dictionnaire en mémoire. On décide plutôt
d'utiliser la stratégie suivante:
- on construit une table de hachage contenant des valeurs
booléennes, table indexée de à M-1 et contenant
initialement FALSE à chacune des positions;
- on lit ensuite le fichier des mots pour définir le contenu de
la table, en mettant à TRUE le booléen associé à
l'indice correspondant à la valeur de hachage d'un mot.
Le pseudo-code de construction de la table est donc le suivant:
POUR h <- 0 A M-1 FAIRE
table[h] <- FALSE
FIN
POUR chacun des mots m du fichier FAIRE
h <- hash(m, M)
table[h] <- TRUE
FIN
[5] a) Est-il possible d'écrire une fonction qui
déterminera, en examinant uniquement la table, si un mot donné est
valide (présent dans le fichier)? Si oui, donnez le pseudo-code de
cette fonction. Si non, expliquez pourquoi cela n'est pas possible.
[5] b) Est-il possible d'écrire une fonction qui
déterminera, en examinant uniquement la table, si un mot donné
est absent du fichier (mot non valide)? Plus précisément, lorsque
cette fonction retournera true, alors le mot sera
nécessairement absent du dictionnaire; par contre, lorsque la
fonction retournera false, alors il est possible que le mot soit
quand même présent. Donnez le pseudo-code de cette fonction. Si
non, expliquez pourquoi cela n'est pas possible.
2. Équations de récurrence (20 pts)
[10] a) Trouvez les
diverses solutions de l'équation de récurrence suivante en
fonction de k (pour k un nombre réel non-négatif):
-
- T(1) = 1
-
- T(n) = 4 T(n/2) + nk
[10] b) Trouvez un estimé 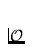 pour l'équation de
récurrence suivante et prouvez par induction qu'il est correct:
pour l'équation de
récurrence suivante et prouvez par induction qu'il est correct:
-
- T(1) = 1
-
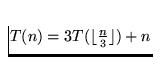
3. Algorithme diviser-pour-régner (15 pts)
En utilisant la
méthode diviser-pour-régner et en vous assurant de bien balancer
la taille des sous-problèmes, concevez un algorithme récursif
permettant de trouver le minimum et le maximum d'un tableau
d'entiers A contenant n éléments (![$A[0], \ldots, A[n-1]$](img3.gif) ) pas
nécessairement en ordre.
) pas
nécessairement en ordre.
Quelle est la complexité asymptotique de votre algorithme?
Justifiez!
Suggestion: Une fonction peut retourner un tuple, une paire
d'éléments.
4. Tri par fusion modifié (10 pts)
La procédure qui suit est
une version modifiée, avec mémorisation, de la procédure de tri
par fusion vue dans le cours (spécialisée pour trier une
séquence d'entiers). On y utilise un dictionnaire dont les clés
sont des séquences d'entiers: deux séquences sont égales si
elles sont de la même longueur et contiennent exactement les mêmes
éléments.
PROCEDURE tri-fusion( s: sequence{int} ) s': sequence{int}
DEBUT
dict <- new Dictionary()
dict.insertItem( [], [] )
RETOURNER tf-memo( s, dict )
FIN
PROCEDURE tf-memo( s: sequence{int}, dict: Dictionary ) s': sequence{int}
DEBUT
r <- dict.findElement( s )
SI r != NO_SUCH_KEY ALORS
RETOURNER r
FIN
m <- length(s) / 2 // Division entiere
s1 <- tf-memo( s[0..m-1], dict )
s2 <- tf-memo( s[m..length(s)-1], dict )
s' <- fusion( s1, s2 )
dict.insertItem( s, s' )
RETOURNER s'
FIN
[5] a) Sachant que la procédure fusion est de
complexité linéaire (la fusion de deux listes de longueur n
prend un temps de complexité 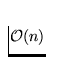 ) et en supposant que la
recherche et l'insertion dans le dictionnaire sont
) et en supposant que la
recherche et l'insertion dans le dictionnaire sont 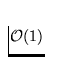 quelle
est la complexité de cet algorithme?
[5] b) Est-ce qu'il s'agit d'une amélioration
asymptotique par rapport à l'algorithme initial? Expliquez pourquoi
l'algorithme est amélioré par la mémorisation ou pourquoi il ne
l'est pas.
quelle
est la complexité de cet algorithme?
[5] b) Est-ce qu'il s'agit d'une amélioration
asymptotique par rapport à l'algorithme initial? Expliquez pourquoi
l'algorithme est amélioré par la mémorisation ou pourquoi il ne
l'est pas.
5. Arbres (10 pts)
La figure 1
présente des arbres binaires. Pour chacun de ces arbres, indiquez:
- 1.
- si l'arbre est un arbre binaire de recherche;
- 2.
- si l'abre est un arbre AVL;
- 3.
- si l'arbre est un arbre 2-4.
brièvement chacune de vos réponses: quelles
propriétés sont satisfaites? quelles propriétés ne le sont
pas?
Figure 1:
Quelques arbres binaires
|
Questions optionnelles: Réponsez à deux (2) questions parmi les
suivantes.
6. Encodage de Huffman (10 pts)
Supposons que l'on désire
encoder une chaîne de caractères à l'aide d'un encodage
ternaire plutôt que binaire (chaque unité d'information
représente l'une des valeurs 0, 1 ou 2: ternary
digits). Dessinez un arbre d'encodage ternaire utilisant
la technique de Huffman pour les caractères et fréquences
indiqués dans la table 1.
Table 1:
Table des caractères et de leurs fréquences
| Caractère |
|
a |
b |
d |
e |
f |
h |
i |
k |
n |
o |
r |
s |
t |
u |
v |
z |
| Fréquence |
9 |
5 |
1 |
3 |
7 |
3 |
1 |
1 |
1 |
4 |
1 |
5 |
1 |
2 |
1 |
1 |
2 |
7. Arbres-(2, 3) (10 pts)
Un arbre-(2, 3) est semblable à un
arbre-(2, 4) à la différence que chaque noeud interne peut avoir
au plus 3 enfants (donc 2 ou 3 enfants).
[5] a) Dessinez un arbre-(2, 3) ayant une hauteur égale
à 2, possédant le nombre maximum de clés possibles et dont les
clés proviennent de la suite 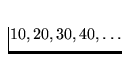 [5] b) Pour un arbre-(2, 3) de hauteur h, quel est le
nombre maximum de clés qui pourront être conservées dans
un tel arbre? Justifiez brièvement.
8. Sélection (10 pts)
Un tableau contient n éléments, pas
nécessairement triés. On désire obtenir m éléments parmi
ces n éléments, plus précisément, on désire obtenir
l'élément médiane ainsi que les m-1 éléments qui suivent
dans l'ordre. En d'autres mots, on veut obtenir les m éléments
suivants dans la suite triée correspondant à ces n éléments:
[5] b) Pour un arbre-(2, 3) de hauteur h, quel est le
nombre maximum de clés qui pourront être conservées dans
un tel arbre? Justifiez brièvement.
8. Sélection (10 pts)
Un tableau contient n éléments, pas
nécessairement triés. On désire obtenir m éléments parmi
ces n éléments, plus précisément, on désire obtenir
l'élément médiane ainsi que les m-1 éléments qui suivent
dans l'ordre. En d'autres mots, on veut obtenir les m éléments
suivants dans la suite triée correspondant à ces n éléments:
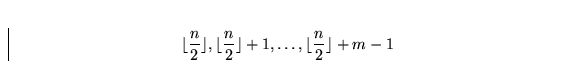
Laquelle des méthodes suivantes serait la plus rapide (en fonction
de m et n):
- 1.
- Trier le tableau n et obtenir les m éléments requis.
- 2.
- Utiliser m fois la méthode quickSelect.
Justifiez brièvement votre réponse.
9. Enveloppes convexes (10 pts)
L'algorithme de Graham pour calculer
l'enveloppe convexe requiert que, une fois le point d'ancrage choisi,
les points restants soient classés en ordre croissant d'angle
relatif au point d'ancrage.
Supposons que l'on choisisse, comme point d'ancrage, le point ayant la
coordonnée y maximum (ainsi que la coordonnée x maximum, si
plusieurs point ont la même coordonnée y maximum).
[5] a) Serait-il nécessaire de modifier l'algorithme
présenté à la section 15.2.3? Si oui, comment? Si non, pourquoi?
[5] b) Supposons de plus que le seul algorithme disponible
pour effectuer le tri des points selon leur angle soit un tri par
sélection. Quelle serait la complexité de l'algorithme de Graham
en utilisant cet algorithme de tri?
10. Tries (10 pts)
Soit l'ensemble suivant de chaînes:
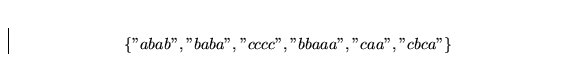
[5] a) Construisez le trie standard représentant cet
ensemble de chaînes.
[5] b) Construisez le trie compressé représentant cet
ensemble de chaînes.
Tremblay Guy
12/21/1998